はじめに
Federated Learningに興味があり色々確認していたのですが、決定木ベースのモデルはないのかと思うようになりました。
探してみると以下の論文が出てきたので、読みました。
メモとしてここで簡単にまとめます。
概要
Federated Learningは、トレーニングデータをローカルのみに保持した状態でネットワーク全体のグローバルモデルを取得することができる
FLには大きく二つの問題がある
- 垂直に分割されたデータを処理できない
- 決定木ベースのアルゴリズムは利用できない
勾配ブースティング決定木(GBDT)によるFL:FederBoostを提案
三つのデータセットで集約データによる学習と同等レベルのAUCを達成
イントロ
Federated Learning(連合学習)は、複数の参加者が観測したデータをやり取りすることなく、全体の情報を利用した学習モデル(グローバルモデル)を得るフレームワーク
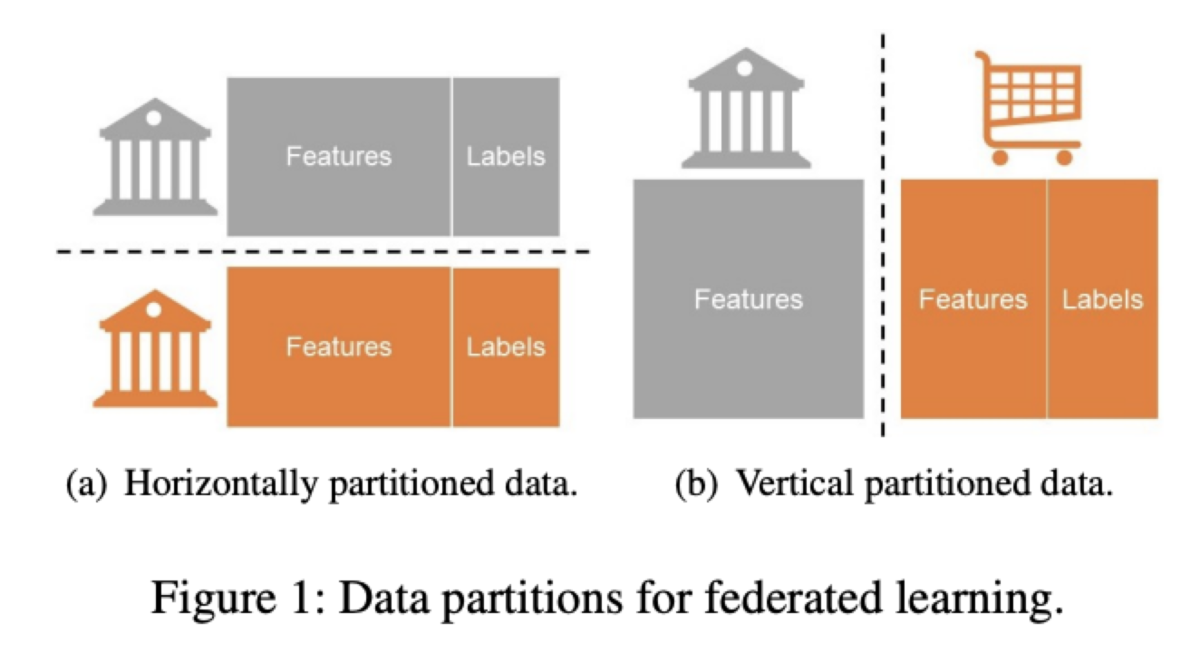
大きく二種類
- 参加者のデータが同じ特徴量保持するが、ローカルごとの参加者が異なるHorizontally FL
- 参加者は共通だが、保持する特徴量がローカルごとに異なるVertical FL
主な貢献は以下 - GBDT Federated Learning フレームワーク:FederBoostを提案
水平方向のFederBoostではバケットを分散して構築する新しい方法を提案
FederBoostの有用性を3つの公開されたデータセットで検証
プールされた全データによる学習と同程度のAUCが得られた
FederBoostの完全な実装を提供し最大32ノードのクラスタに展開し、1つのGBDTモデルは、WAN環境下でも30分以内で学習可能
事前知識
GBDT
Gradient boosting decision tree(GBDT)は決定技のアンサンブルモデルである。
推定値は以下のように表現される。
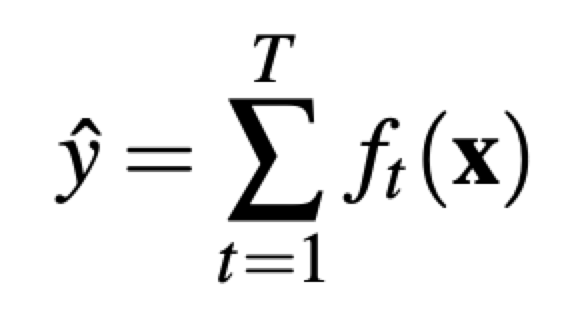
GBDTは各決定木における1次勾配と2次勾配
を用いて、決定木の分割を行なっていく。

以下の評価関数を最大にするような分割を探索していく。

はハイパーパラメータ,
は左の子ノードに分割されたサンプル,
は右の子ノードに分割されたサンプルを表す。
なお、全体サンプルはソートされている。
ほとんどのGBDTフレームワークでは、学習プロセスを速くするために、各特徴の勾配の統計量を要約し勾配ヒストグラム,
で構築する動作を加えている。

学習アルゴリズムの流れは以下のようになっている。

Federated learning
horizontal FLは2017年にGoogleが提案されたものが代表的。
中央(パラメータ)サーバと参加者の二者が存在する。
最初に中央サーバはランダムな値でモデルを初期化し、すべての参加者に送信する。
各は受信したモデルを用いそれぞれで学習する。
その際に生成された勾配をパラメータサーバに送信し、中央サーバは受信した勾配を集計、グローバルモデルを更新することができる。
Secure aggregation
水平FLにおける局所勾配を保護した形で集計するプロトコルが提案されている
参加者の局所勾配を保護するためにペア加法的マスキングを使用し,マスキングされた入力をサーバに集約させる。
共有されたシード値を用いた擬似乱数生成器(PRG)を利用しマスクされ、乱数による影響は集計によりキャンセルされる。
Differential privacy
差分プライバシーは、各個人のデータを保護しながら統計的分析を可能する手法/分野。
各個人/ノードのデータに対して乱数により発生させたノイズを負荷することで可能になる。
差分プライバシーのプライバシー保護度合い等を定義した考え方として、Differential privacyが挙げられる。

設定
環境の設定
FLの設定
従来の分散型MLに近い効率、すなわち暗号処理回数を最小にする
精度は集中型学習に近いものであるべき
プライバシー保護レベルはローカル学習(各参加者が自分のローカルデータのみで学習)に近いものであるべき そのためには、転送されるデータを暗号化技術や差分プライバシーで保護する必要がある。
Vertical FederBoost
学習
決定木を構築するための重要なステップは、特徴量に対するサンプルの最適な分割を見つけることであり、これにはサンプルの順序と1次と2次の勾配 ,
だけが必要。
各参加者に特徴量のサンプルを並べ替えてもらい、その順番をに伝えることができれば全体の学習を完了することができる。
参加者はサンプルの値は必要なく、順番を伝えるだけで良いので、情報量が格段に少なくなる。
一方で、順序情報からの情報漏洩する可能性が残っている。
例えば特徴量が"給与"とすると、はこのような情報を得ることができる。
アリスの給料 ≦ ボブの給料 ≦ シャーリィの給料
もしがアリスの給料とシャーリィの給料を知っていれば、ボブの給料(または少なくともその範囲)を推論することができてしまう。
このような情報漏洩を防ぐために、サンプルをバケットに入れる方法と、差分プライバシーノイズを加える方法の2つを組み合わせる。
バスケット化
差分プライバシーノイズ付加
元々
番目のバスケットに割り当てられていたサンプルに対して
確率
で
確率
で
この方式は任意の2つのサンプル
に対して以下の
-LDPを満たすことになる

実験結果(セクション6.1参照)はε=2、q=16とした場合、垂直方向の FederBoost は DP を用いない場合と非常に近い値を示した。
学習の全体像

Vertical FBの学習アルゴリズムは以下のようになっている。

8-24行目: Plは集中型GBDTと全く同じ方法で学習アルゴリズムを実行
推論
予測フェーズでは、個の決定木すべてに
を入力し予測値を出力する。
このために分割の閾値と特徴量を比較し、どのノードに進むか判断する必要がある。
具体的には
ルートから始めて
は判断に必要な特徴を保持している
に連絡
と閾値を比較し、
その結果に基づいて
プライバシー保護について
Horizontal FederBoost
学習の全体像は以下の図のようになっている。

各サンプルは全ての特徴量とラベルを持つ。
参加者が各ローカルでモデルを学習し、ローカルで学習したモデルを中央サーバで集計し、グローバルな共同モデルを生成する。
また、参加者の各ローカルで決定木を学習しバギングするランダムフォレストも一致する。
しかし、ランダムフォレストを学習するためには、各参加者が全サンプルの63.2%以上を保有している必要があり、これはFLの設定と矛盾している。
課題が2つ
分散バケット構築
従来の分散型GBDTにおける分散バケット構築の最も一般的な方法は、分位点スケッチと呼ばれ、各参加者が自分のローカルデータの表現を送信して、各特徴の分布を近似することが要求される。
しかし、この方法では、参加者のローカルデータに関する情報がリークしていまう。
そこで、プライバシーを保護するため分散バケット構築法を提案。
基本的な考え方は、ある特徴量のn個のサンプル値をq個のバケットに分割するカットポイント(分位数)を求め、参加者はその分位数に基づき対応するバケットにサンプルを入れる。
のすべての分位数を求める擬似コード をプロトコール 3 に示す。

6-8行目:
より小さいサンプル
を求める。
9行目:各ローカルの該当件数からセキュアな集計を行う
16-18行目:
学習
水平FederBoostではバケット構築も一度だけ行う。
参加者はデータが変更されない限り、モデルを微調整するためにトレーニングフェーズを複数回実行する。
全ての分位数を求めた後、各参加者はローカルで自分のサンプルIDを角バケットに入れることができ、はそのバケットの情報を集めて集計することができる。
一方で各参加者は全てのラベルを保持していないため、vertical FederBoostのように決定木を学習させることはしない。

1行目から9行目まではセットアップの段階。
1-3行目:Quantile Lookup(プロトコル3)でバスケットの取得
8-9 行目:各
と
を計算する
18 行目:各バケットの
と
を計算
22行目:各参加者から集められた
と
から評価値
と分割位置
を各バケットのを計算
24-25行目:各参加者に
27 行目:形成された木のノードの重みにより推定値
を修正する
また、secure aggrigation(プロトコル5)は以下のようになっている。

プライバシー保護について
実装と実験
3つの公開データセットで実験を行った。
ツリーの数はT=20と設定
有用性の検証
バスケット数を変化させた時に、FederBoostと集約データを用いたXGBoostを比較。
水平垂直ともに集約した場合と大きな性能差は確認されず。


バスケットの数を16に固定し、差分プライバシーレベルの値を変化させた場合の予測精度を確認
Credit1とCredit2は=2で、BC-TCGA-Tumorは
=1の場合まで保護レベルを下げることで精度に差がなくなる。

効率性の確認
最大32のプロセスを生成し、各プロセスは単一の参加者と仮定した。
各プロセスとの通信はローカルエリアネットワーク(LAN)と通信速度を制限した擬似的なワイドエリアネットワーク (WAN)を仮定。
LAN設定の場合の結果
Credit1とCredit2は23特徴量のみであるため、Vertical FLにおいてローカル数は10までのみとなっている。


WAN設定の場合の結果
通信速度は20Mbit/sであり、100msの遅延が存在していると仮定している。

Horizontal FLにおけるTumorの場合、特徴量が多く、各特徴の分位数の決定と勾配計算のために計算量がかかりすぎるため、実験は実施していない模様。
